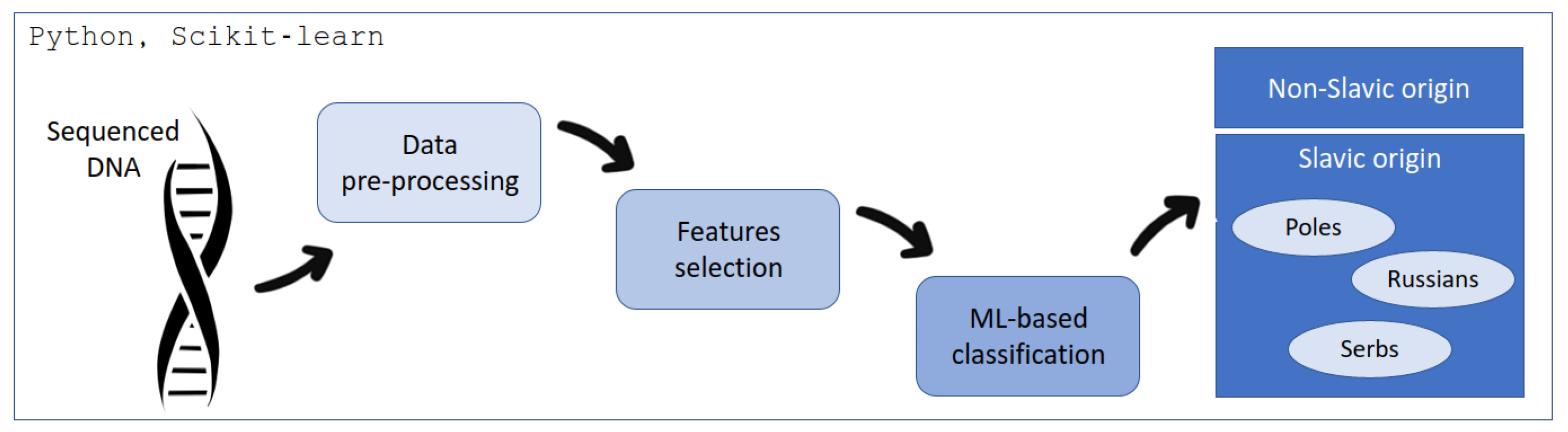
DNA classification using Machine Learning
This project provides a structured approach to DNA sequence classification using machine learning techniques, from data preprocessing to model evaluation. It explores multiple algorithms, including K-Nearest Neighbors, Support Vector Machine, Decision Trees, Random Forest, Naive Bayes, MultiLayer Perceptron, and AdaBoost, to identify the most effective model for the task. The models are assessed based on metrics like accuracy, precision, recall, and F1 score, with the Support Vector Machine (linear kernel) emerging as the top performer, achieving an impressive F1 score of 0.96. This work highlights the potential of machine learning in bioinformatics for accurate DNA classification.