
Posts by Collection
interview_preparation
Calculus And Algorithmic Differentiation
Contains questions from calculus and differentiation
Computer Science Questions
This section covers key computer science concepts, including recursive functions, sorting algorithms, and subsequence problems. It also explores matrix multiplication optimization, numerical stability in deep learning, and the benefits of GPUs versus TPUs. Additionally, it addresses practical challenges like dynamic memory management and file similarity filtering.
Convolution Neural Networks
This is a comprehensive set of questions related to Convolutional Neural Networks (CNNs), covering various aspects from convolution operations to fine-tuning pre-trained models and neural style transfer. Each question is well-defined, and the use of images and code snippets adds depth to the understanding of the concepts.
Descriptive Statistics
Mean, Median, Variance, Data distribution etc.
General Concepts In Machine Learning
Contains questions from Bias and Variance, Cross Validation, Sampling Techniques etc
General Concepts In Neural Networks
This section covers Neural Networks, Activation Function, Dropout, Regularization and other crucial topics related to neural nets
Inferential Statistics
This section covers Point Estimation, Interval Estimation, Hypothesis Testing and Inference for Relationship
Information Theory
This section covers KL-Divergence Theorem, Entropy, Information Gain, Gini Impurity etc.
Linear Methods For Classification
Logistic Regression
Linear Methods For Regression
Covers questions from Linear Regression, Bias and Variance, Regularization, Feature Selection etc.
Natural Language Processing
Contains questions from Tokenization, Tf-Idf, Embeddings, Other NLP concepts
Performance Metrics
Covers questions from Regression Metrics, Classification Metrics, Loss Functions, Objective Functions, Clustering Metrics
Probability
Questions from probability, conditional probability, bayes theorem, total probability etc
Probabilistic Modeling
Questions from Naive Bayes
SQL
This section covers key SQL topics like data retrieval, string manipulation, joins, subqueries, sorting, filtering, and aggregation using functions like COUNT and GROUP BY. It also explores advanced operations like ranking, conditional logic, and handling duplicates, essential for data analysis.
Support Vector Machines
This Q&A covers fundamental concepts of Support Vector Machines (SVM) and Support Vector Regression (SVR). It includes topics such as the maximal margin classifier, hyperplanes, margin optimization, support vectors, and kernel functions. Additionally, it explores the differences between SVM and SVR, including their applications, loss functions, hyperparameters, and how they handle non-linear boundaries and outliers.
Tree Based Methods
This section contains questions from Decision Trees, Bagging, Boosting, Random Forest, XGBoost, Adaboost, Gradient Boosting
Unsupervised Learning
This section covers concepts from Dimensionality Reduction, Autoencoders, PCA, Clustering, KMeans, Recommendation System topics
Vector and Matrices
This section covers concepts related to Vector and Matrices
projects
DNA classification using Machine Learning
This project provides a structured approach to DNA sequence classification using machine learning techniques, from data preprocessing to model evaluation. It explores multiple algorithms, including K-Nearest Neighbors, Support Vector Machine, Decision Trees, Random Forest, Naive Bayes, MultiLayer Perceptron, and AdaBoost, to identify the most effective model for the task. The models are assessed based on metrics like accuracy, precision, recall, and F1 score, with the Support Vector Machine (linear kernel) emerging as the top performer, achieving an impressive F1 score of 0.96. This work highlights the potential of machine learning in bioinformatics for accurate DNA classification.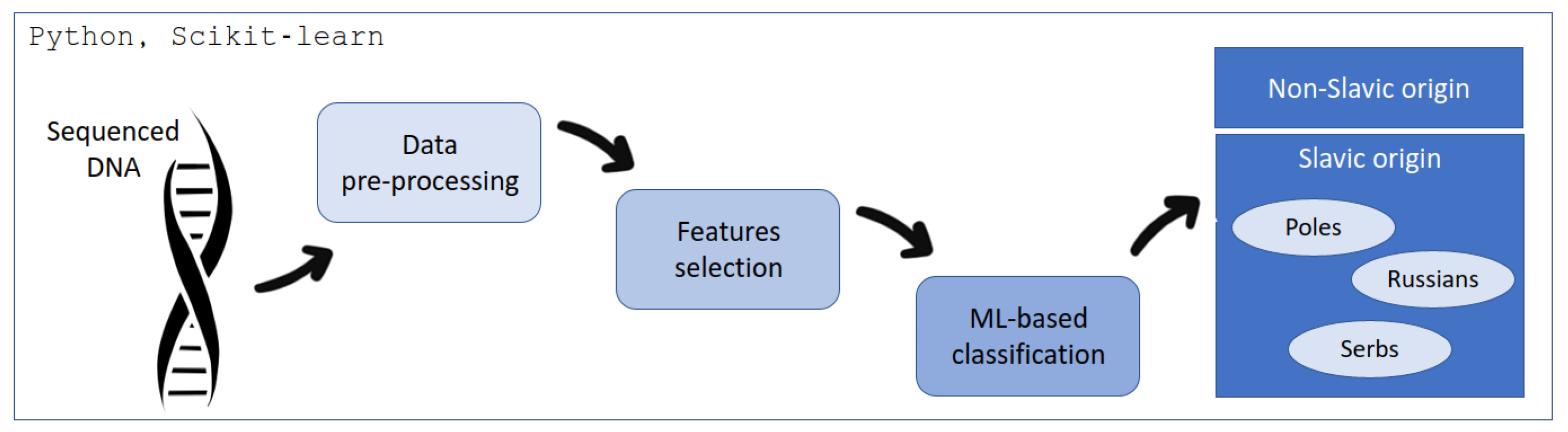
Performance Metric in Machine Learning Related Tasks
This repository offers a comprehensive collection of performance metrics for evaluating machine learning models across various tasks, including regression, classification, clustering, and sequence prediction. It features commonly used metrics like Mean Squared Error, Accuracy, Precision, and Silhouette Coefficient, among others, to help you assess and improve your models’ effectiveness.
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.